
𝗧𝗵𝗲 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗲𝘀 𝗕𝗲𝗵𝗶𝗻𝗱 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗩𝗟𝗠𝘀)

Ever wondered how Vision Language Models actually learn to understand both images and text?
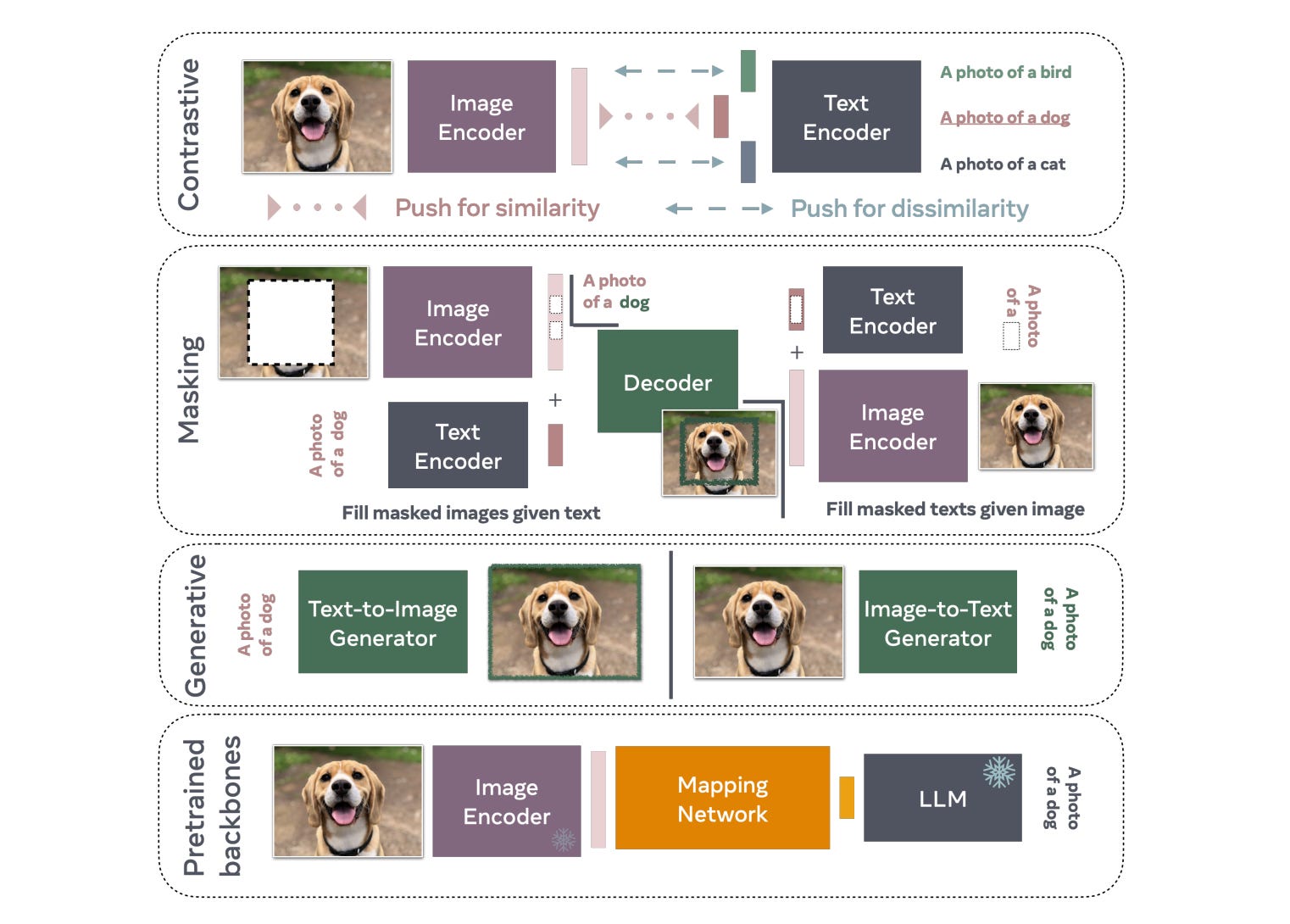
Below are the training approaches, each with distinct strengths:
1️⃣ Contrastive Learning – These models learn by matching similar image-text pairs while pushing apart dissimilar ones. Think CLIP and its variants. They’re relatively inexpensive to train and excel at tasks like image search and zero-shot classification.
2️⃣ Masking-Based Learning – By filling in the blanks, models reconstruct missing image patches from text descriptions or predict masked words from images. This bidirectional approach develops a deeper understanding of the relationship between visual and textual information.
3️⃣ Generative Models – Can generate complete images from text or produce detailed captions from images. Most expensive to train but offer the most flexibility for creative tasks. DALL-E and modern image captioning systems fall into this category.
4️⃣ Pretrained Backbone Approaches – The practical integrators. Leverage existing pretrained models like open-source LLMs (Llama, for example) and learn a mapping network to connect vision encoders with language models. Reduces training costs by building on proven foundations.
Understanding these training paradigms helps you choose the right model for your application. Need fast zero-shot classification? Go contrastive. Building a captioning system? Consider generative or masking approaches. Working with limited compute? Pretrained backbones might be your answer.
Paper link: https://arxiv.org/html/2405.17247v1#S1