
Object detection with Multimodal Large Vision-Language Models: An in-depth review

The world of computer vision is experiencing a revolutionary transformation. For years, object detection systems have relied on traditional deep learning architectures like YOLO, Faster R-CNN, and Mask R-CNN. These models have achieved remarkable success in identifying and localizing objects within images. However, they all share a fundamental limitation: they can only detect objects they’ve been explicitly trained to recognize.
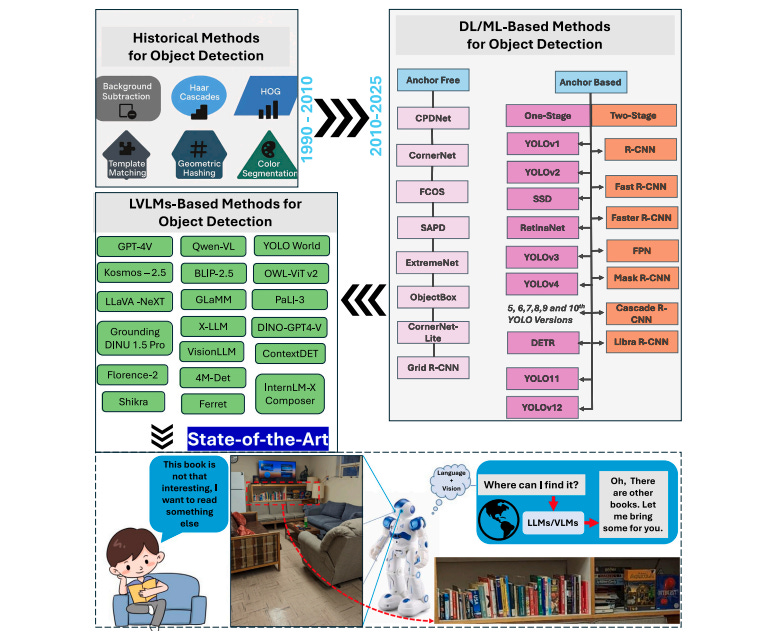
Enter Large Vision-Language Models (LVLMs), a groundbreaking fusion of computer vision and natural language processing that’s fundamentally changing how machines perceive and understand visual content. These models don’t just see objects—they comprehend context, interpret instructions, and reason about visual scenes in ways that traditional systems simply cannot.
From Traditional Detection to Multimodal Understanding
The journey of object detection has been fascinating. In the early days, methods like Background Subtraction and Histogram of Oriented Gradients (HOG) provided the foundation, but they struggled with variations in lighting, orientation, and scale. The deep learning revolution brought models like YOLO and Mask R-CNN, which dramatically improved accuracy and speed. Yet these models remained constrained by their training data—unable to detect objects outside their predefined categories.
LVLMs represent the next evolutionary leap. By integrating language models that facilitate robust fusion of visual and textual data, these systems can interpret images not merely as arrays of pixels, but as entities embedded with contextual information describable in natural language. This capability transforms object detection from a pattern recognition task into a reasoning process.
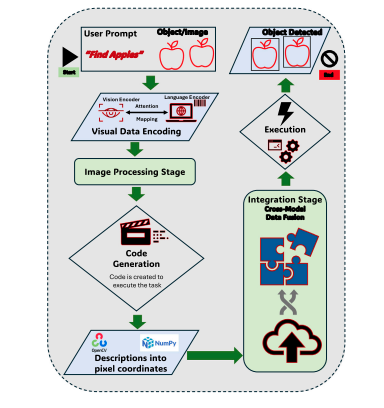
How LVLMs Actually Work for Object Detection
The process of object detection with LVLMs is elegantly sophisticated. When you prompt a system like GPT-4V or LLaVA to “find apples” in an image, a complex chain of operations unfolds. First, a visual encoder analyzes the image to extract relevant features. Simultaneously, a language encoder processes the textual prompt. An attention mechanism then aligns these modalities, ensuring the system focuses on image regions that match the textual description.
What makes this particularly powerful is the code generation capability of some recent LVLMs. Rather than directly producing bounding boxes, these models can reason through multimodal prompts to generate executable code snippets for tasks like drawing bounding boxes or querying object attributes. This approach, seen in models like DetGPT, allows the LVLM to operate not just as a perception system but as a cognitive planner, translating user intent and scene context into structured actions.
The conversion of high-level model insights into actionable data points is where tools like OpenCV and NumPy come into play, transforming attention maps into precise pixel coordinates. This crucial transition enables the creation of accurate bounding boxes around detected objects, bridging the gap between semantic understanding and spatial precision.
Architectural Innovations Driving Progress
The architectural landscape of LVLMs for object detection reveals several key innovations. Dual-stream architectures process visual and textual data through separate pathways before integration, allowing dynamic adjustment of weights between modalities. This design choice proves critical for tasks requiring detailed understanding of both visual content and language instructions.
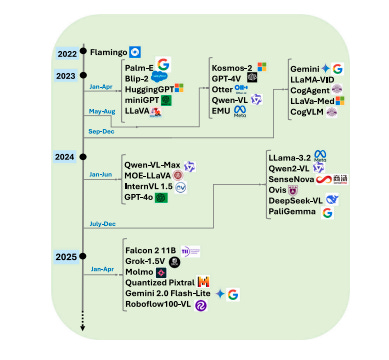
At the core of many LVLMs sits the transformer architecture, adapted from natural language processing to handle mixed data types. By processing images as sequences of patches and descriptions as sequences of tokens, these models achieve contextually rich interpretations that far exceed traditional approaches. Models like Kosmos-2.5 demonstrate zero-shot detection capabilities through spatial tokens, achieving impressive results without seeing specific object categories during training.
The attention mechanisms incorporated into these architectures focus on relevant image parts in relation to textual descriptions. This feature proves crucial for zero-shot object detection, where models predict objects never encountered during training. ContextDET, for instance, introduces a generate-then-detect framework that employs a visual encoder for high-level image representation, a pre-trained LLM for text generation, and a visual decoder to compute conditional object queries.
Real-World Applications and Capabilities
The practical applications of LVLM-based object detection span numerous domains, each demonstrating unique advantages over traditional approaches. In autonomous driving, the VOLTRON model integrates YOLOv8 with LLaMA2 to enhance real-time hazard identification, significantly improving object detection accuracy in dynamic traffic scenarios. This fusion approach demonstrates how LVLMs can adapt to safety-critical applications requiring both speed and contextual understanding.

Remote sensing represents another domain where LVLMs excel. Traditional object detection models struggle with the unique challenges of high-resolution satellite imagery and diverse object scales. GeoChat, a grounded vision-language model tailored for remote sensing, addresses these challenges through robust zero-shot performance across tasks including object detection, visually relevant conversations, and scene classification. The model’s ability to handle multi-task conversational capabilities while maintaining accuracy demonstrates the versatility of LVLMs in specialized domains.
In robotics, DetGPT showcases how reasoning-based detection can enhance human-AI interaction. The model’s multimodal encoder-decoder architecture enables more effective autonomous navigation and query-based searches, illustrating how LVLMs create more interactive and capable robotic systems. This advancement proves particularly valuable in scenarios where robots must interpret human intent and respond to complex, context-dependent instructions.
The Performance Trade-Off Reality
While LVLMs offer remarkable capabilities, they come with significant trade-offs that practitioners must understand. Traditional models like YOLOv8 achieve real-time performance at 100 FPS on an NVIDIA V100 GPU, making them suitable for edge deployment and mobile applications. In contrast, LVLMs typically require server-grade GPUs with 16-80 GB VRAM and achieve substantially lower inference speeds.
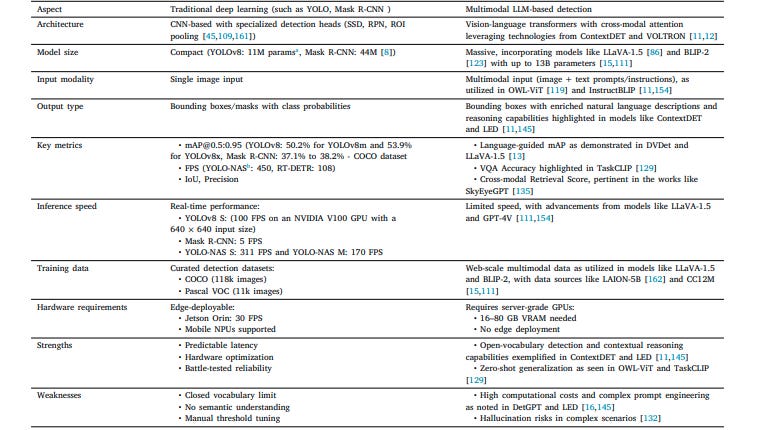
The computational requirements stem from the massive parameter counts of these models. While YOLOv8 operates with just 11 million parameters, models like LLaVA-1.5 and BLIP-2 contain up to 13 billion parameters. This difference translates directly into memory usage, processing time, and deployment complexity. For applications requiring predictable latency and real-time processing, traditional models often remain the better choice.
However, the advantages of LVLMs become apparent in their open-vocabulary capabilities and contextual reasoning. Traditional models struggle with queries like “Find the object that shouldn’t be here” or “Is the leash attached to the dog?” because they lack semantic reasoning beyond isolated object identification. LVLMs excel in these scenarios, leveraging cross-modal attention to link specific words to corresponding image regions and enabling language-driven visualization that traditional frameworks cannot provide.
Challenges and the Path Forward
Despite their impressive capabilities, LVLMs face several critical challenges that limit their widespread adoption. Hallucination remains a persistent issue, where models generate false detections due to ambiguous language cues or multimodal mismatches. The MERLIM benchmark reports a 22% error rate in relational understanding, highlighting this limitation. While models like Grounding DINO propose contrastive alignment and grounding losses as solutions, robust testing across dynamic, compositional prompts remains inconsistent.
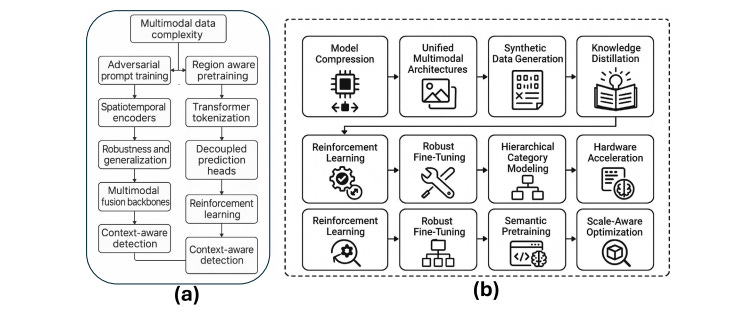
Spatial mislocalization presents another significant challenge. Hybrid methods like DetGPT and OV-DETR attempt to address this by combining coarse VLM priors with conventional detectors, but these approaches often rely on handcrafted thresholds that prove difficult to generalize across domains. The domain gap between image-level supervision during pretraining and the region-level precision required for object detection further complicates deployment.
The path forward likely involves several complementary strategies. Model compression techniques including quantization, pruning, and knowledge distillation could enable LVLM deployment on edge devices. LoRA-based tuning offers parameter-efficient fine-tuning by updating only small trainable matrices within transformer layers, making adaptation more accessible. Reinforcement learning with carefully designed reward functions shows promise for improving localization precision and reducing hallucinations.
Addressing the training data challenge requires innovative approaches to synthetic data generation and few-shot learning. Models trained on semantically complex datasets like D3, rather than simple category labels, demonstrate stronger reasoning chains during detection. The integration of scene graph encoders and hierarchical reasoning layers could preserve contextual information while enabling precise region-level understanding.
A Hybrid Future
The evidence suggests that the future of object detection lies not in choosing between traditional deep learning and LVLMs, but in intelligently combining both approaches. Traditional models excel at rapid, precise localization of known object categories, while LVLMs provide unmatched contextual understanding and open-vocabulary capabilities. A hybrid architecture could leverage LVLMs for high-level reasoning, scene understanding, and novel object discovery, while deploying efficient traditional detectors for precise spatial localization and real-time processing.
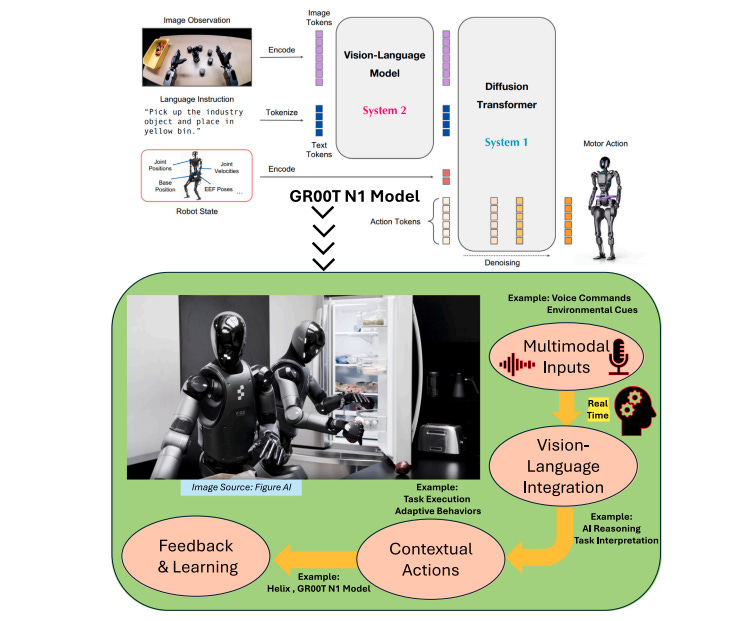
This hybrid approach becomes particularly compelling in robotics applications. Systems like NVIDIA’s GR00T N1 demonstrate how vision-language-action models can integrate multimodal reasoning with precise motor control. The robot’s ability to process visual observations and language instructions through an LVLM backbone, then generate precise actions via a Diffusion Transformer, exemplifies the seamless integration possible between contextual understanding and spatial precision.
The emergence of benchmarks like Roboflow100-VL, MM-Ego, and MERLIM provides crucial infrastructure for evaluating and comparing different approaches. These benchmarks assess not just detection accuracy, but also hallucination rates, compositional reasoning, and performance under real-world perturbations. As the field matures, such comprehensive evaluation frameworks will guide the development of more robust, reliable systems.
Conclusion:
The integration of vision and language in LVLMs represents a fundamental shift in how machines perceive and interact with the visual world. While traditional object detection models will continue to play vital roles in applications requiring speed and precision, LVLMs open new frontiers in contextual reasoning, zero-shot generalization, and natural human-machine interaction.
The challenges ahead are substantial: reducing computational costs, improving spatial precision, eliminating hallucinations, and bridging the gap between pretraining objectives and detection requirements. Yet the progress over the past three years has been remarkable, with dozens of innovative architectures and training paradigms emerging to address these limitations.
As we move forward, the most successful object detection systems will likely be those that thoughtfully combine the complementary strengths of both paradigms. In domains like autonomous vehicles, elderly care, disaster response, and interactive robotics, this hybrid approach could finally deliver the adaptive, context-aware, and reliable perception systems that have long been the goal of computer vision research.
The revolution in object detection is not about replacing one technology with another, but about expanding our toolkit to handle the full complexity of real-world visual understanding. LVLMs give machines the ability to not just see, but to comprehend, reason, and respond with unprecedented sophistication. That transformation, while still unfolding, promises to reshape automation, robotics, and human-computer interaction in profound ways.
Read the Full Research Paper: https://arxiv.org/abs/2508.19294