

The object detection landscape is experiencing a fundamental shift. For years, CNN-based architectures like YOLO have dominated practical applications, but transformer-based models are now challenging this supremacy. A recent research paper provides the first direct comparison between RF-DETR, the newest transformer-based detector, and YOLOv12, the latest evolution in the YOLO family. This comparison reveals critical differences in how these architectures approach object detection and when to use each one.
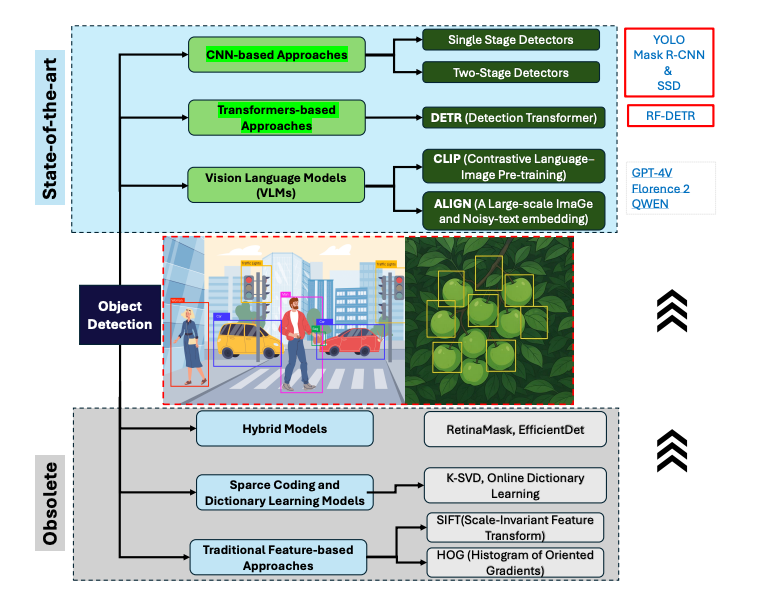
This diagram positions both models within the broader ecosystem of object detection approaches. While CNNs and transformers represent state-of-the-art methods, vision language models are emerging as the next frontier. The study focuses on these two dominant paradigms to understand their relative strengths and limitations.
The Fundamental Architecture Divide
The comparison between RF-DETR and YOLOv12 represents more than just two models. It represents two fundamentally different philosophies in how neural networks should process visual information.
RF-DETR: The Transformer Approach
RF-DETR, developed by Roboflow, builds upon the DETR (Detection Transformer) family. At its core, the model treats object detection as a set prediction problem rather than a spatial grid problem. The architecture employs a DINOv2 vision transformer backbone that has been pre-trained using self-supervised learning, giving it strong generalization capabilities across domains.
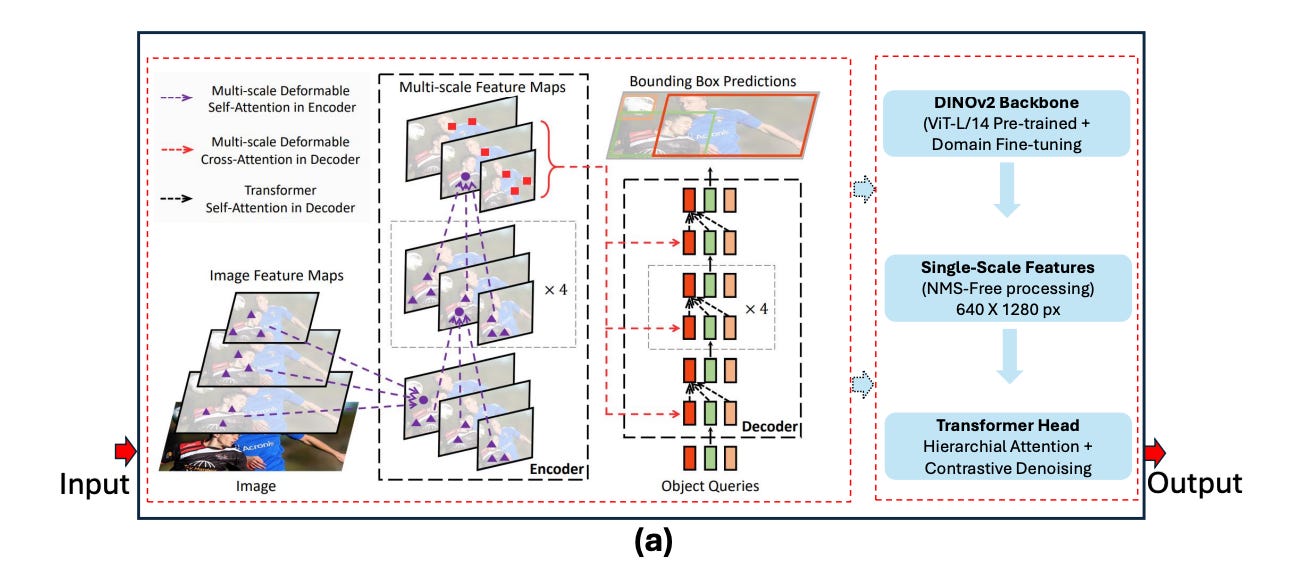
The architecture flows through several key stages. First, the DINOv2 backbone extracts single-scale features from the input image. Unlike traditional CNNs that build hierarchical feature pyramids, RF-DETR works with a unified feature representation. These features then pass through a transformer encoder-decoder structure with deformable attention mechanisms. The decoder uses learned object queries to predict objects in parallel, eliminating the need for anchor boxes or non-maximum suppression.
The deformable attention mechanism represents a crucial innovation. Instead of computing attention across every spatial location, which would be computationally prohibitive, it samples a small set of key points around reference locations. This allows the model to focus computational resources on relevant regions while maintaining a global receptive field from the very first layer.
YOLOv12: The CNN Evolution
YOLOv12 represents the culmination of over a decade of YOLO development. While maintaining the single-shot detection philosophy that made YOLO famous, this iteration introduces several architectural innovations that blur the line between pure CNNs and attention-based models.
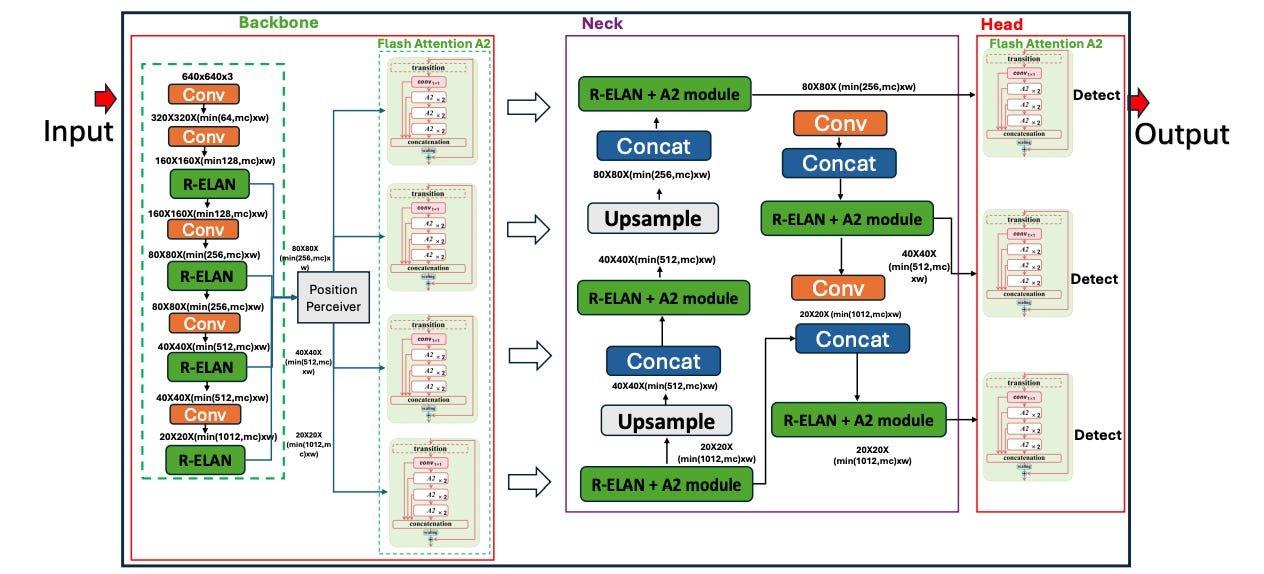
The backbone uses R-ELAN (Residual Efficient Layer Aggregation Network), which combines residual connections with multi-scale feature fusion. This addresses gradient bottleneck issues while enhancing feature reuse across network depths. A notable innovation is the introduction of 7×7 separable convolutions that replace standard 3×3 kernels in certain layers. These larger kernels capture more spatial context while using 60% fewer parameters than traditional large-kernel convolutions.
The neck architecture incorporates FlashAttention-optimized area attention, which divides feature maps into horizontal and vertical regions for localized processing. This provides some of the benefits of self-attention without the computational overhead of processing every pixel relationship. The architecture achieves 40% reduced memory overhead compared to standard self-attention implementations.
Performance Benchmarks: Beyond Simple Metrics
The research evaluated both models using identical training protocols, datasets, and hyperparameters. Training was conducted on an Intel Core i9-10900K with an NVIDIA RTX A5000 GPU. This controlled setup eliminates variables that could skew results, providing a fair comparison between the architectures.
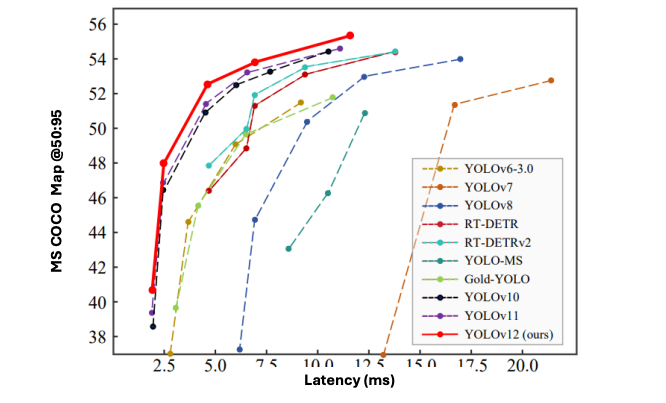
This benchmark visualization places both models within the broader landscape of recent detectors including YOLOv11, RT-DETR, and Gold-YOLO. The chart reveals an interesting pattern: while YOLOv12 variants cluster in the mid-latency, high-accuracy region, RF-DETR pushes the accuracy boundary at the cost of slightly higher latency.
Single-Class Detection Performance
In the single-class detection scenario, RF-DETR achieved an mAP@50 of 0.9464, outperforming all YOLOv12 variants. YOLOv12X achieved 0.9250, YOLOv12L reached 0.9340, and YOLOv12N scored 0.9260. This metric measures how well models localize objects with at least 50% intersection over union with ground truth.
However, when examining mAP@50:95, which averages precision across IoU thresholds from 50% to 95%, YOLOv12N achieved the highest score of 0.7620, slightly edging out RF-DETR’s 0.7433. This suggests that while RF-DETR excels at confident detections with good spatial overlap, YOLOv12 maintains more consistent performance across stricter overlap requirements.
Multi-Class Detection Performance
The multi-class scenario introduced a classification challenge where objects were categorized as either occluded or non-occluded. This tests not only detection capability but also the model’s ability to understand object state and visibility.
RF-DETR achieved the highest mAP@50 of 0.8298, demonstrating superior spatial detection accuracy even when classification complexity increases. YOLOv12X achieved 0.8190, YOLOv12L reached 0.8170, and YOLOv12N scored 0.7910. The performance gap widened in multi-class scenarios, suggesting that RF-DETR’s global context modeling provides advantages when distinguishing between subtle visual differences.
For mAP@50:95, YOLOv12L achieved the highest score of 0.6622, marginally outperforming YOLOv12X at 0.6609 and RF-DETR at 0.6530. This pattern repeats from the single-class results, where YOLOv12 variants maintain slight advantages in strict localization scenarios.
Architectural Analysis: Why These Differences Exist
Understanding why these models perform differently requires examining their fundamental architectural principles.
Global vs Local Processing
The most fundamental difference lies in how each architecture processes spatial information. CNNs, including YOLOv12, build understanding through hierarchical local processing. Early layers detect edges and textures within small receptive fields. Middle layers combine these into patterns like corners and simple shapes. Deep layers aggregate these into complex object representations. This hierarchical approach excels at capturing local patterns and building spatial hierarchies.
Transformers process images fundamentally differently. From the first layer, they can relate any image patch to any other patch through attention mechanisms. This global receptive field allows the model to understand long-range relationships immediately. An object partially visible in one corner can be related to context in the opposite corner without requiring information to propagate through multiple layers.
This architectural difference explains many observed behaviors. When objects are heavily occluded, understanding requires integrating information from distant spatial locations. Transformers handle this naturally through their attention mechanism. CNNs must propagate information through many layers, potentially losing subtle signals along the way.
Attention Mechanisms and Feature Extraction
RF-DETR’s deformable attention learns to sample relevant spatial locations dynamically. For each query, the model identifies which image regions are most informative and focuses computational resources there. This adaptive processing allows efficient allocation of model capacity to difficult regions while using minimal computation on simple backgrounds.
YOLOv12’s area attention divides feature maps into predefined regions for processing. While more efficient than full self-attention, this approach loses the dynamic adaptability of learned attention. The model must process all regions with equal computational effort regardless of their importance to the detection task.
The DINOv2 backbone in RF-DETR provides another advantage. Through self-supervised learning on massive datasets, it develops robust feature representations that generalize across domains. When fine-tuned for specific tasks, these pre-trained features require less adaptation than training from scratch.
YOLOv12’s R-ELAN backbone, while highly optimized, typically trains from random initialization or ImageNet pre-training. This provides less domain-general knowledge, potentially requiring more task-specific data to achieve similar performance.
End-to-End Processing vs Post-Processing
RF-DETR performs detection end-to-end through set prediction. The model predicts a fixed number of object candidates, automatically learning to suppress empty predictions. This eliminates the need for hand-crafted post-processing like non-maximum suppression, which can introduce errors when objects overlap heavily.
YOLOv12, despite optimizations, still relies on anchor-based detection and post-processing steps. While efficient, these components add hyperparameters that must be tuned for specific scenarios. The model predicts many overlapping boxes that must be filtered through NMS, which can fail in edge cases like tightly clustered objects.
Computational Efficiency and Deployment Considerations
Performance metrics only tell part of the story. Real-world deployment requires considering computational requirements, memory footprint, and inference speed.
RF-DETR-Base with 29 million parameters achieves 25 FPS on an NVIDIA T4 GPU. For applications requiring high accuracy and moderate speed, this performance suffices. The model’s memory requirements fit comfortably on modern GPUs, making it deployable in cloud or edge server environments.
YOLOv12 offers more granular options. The 12n variant with only 2.1 million parameters achieves sub-10ms inference on edge devices, making it suitable for mobile phones and embedded systems. The 12s variant processes 4K video at 45 FPS on the same T4 GPU, significantly faster than RF-DETR.
This speed difference stems from architectural choices. CNNs use operations highly optimized in modern hardware. Convolutional layers, pooling, and batch normalization all have efficient implementations in CUDA and specialized AI accelerators. Transformers require attention operations that are more memory-intensive and less hardware-optimized, though this gap is closing with specialized implementations.
For batch processing or offline analysis, RF-DETR’s accuracy advantages often outweigh speed considerations. For real-time applications like autonomous vehicles or live video analysis, YOLOv12’s speed becomes critical. The choice depends on whether your bottleneck is accuracy or latency.
Future Trajectory: Where Object Detection Is Heading
This comparison reveals broader trends shaping computer vision’s future.
Transformer adoption in production is accelerating. RF-DETR demonstrates that transformers can match or exceed CNN performance in real-world applications, not just academic benchmarks. As training efficiency improves and inference optimization progresses, we’ll see transformers deployed more widely in production systems.
Hybrid architectures represent the next evolution. Models combining CNN efficiency with transformer global modeling will likely dominate. We’re already seeing this with RT-DETR and YOLOv12’s attention mechanisms. Future architectures will more seamlessly blend both paradigms, taking the best of each approach.
Vision-language models promise to revolutionize object detection. Models like OWL-ViT enable open-vocabulary detection, identifying objects described by text without retraining. This flexibility would allow a single model to handle diverse detection tasks, dramatically reducing deployment complexity.
Few-shot and semi-supervised learning will reduce annotation burden. Label ambiguity highlighted how expensive and imperfect manual annotation can be. Models that learn from limited labeled data or leverage large unlabeled datasets will make detection systems more accessible.
Edge deployment optimization will continue. Transformers need further efficiency improvements for mobile devices. We’ll see specialized architectures, quantization techniques, and hardware accelerators specifically designed for transformer operations, closing the efficiency gap with CNNs.